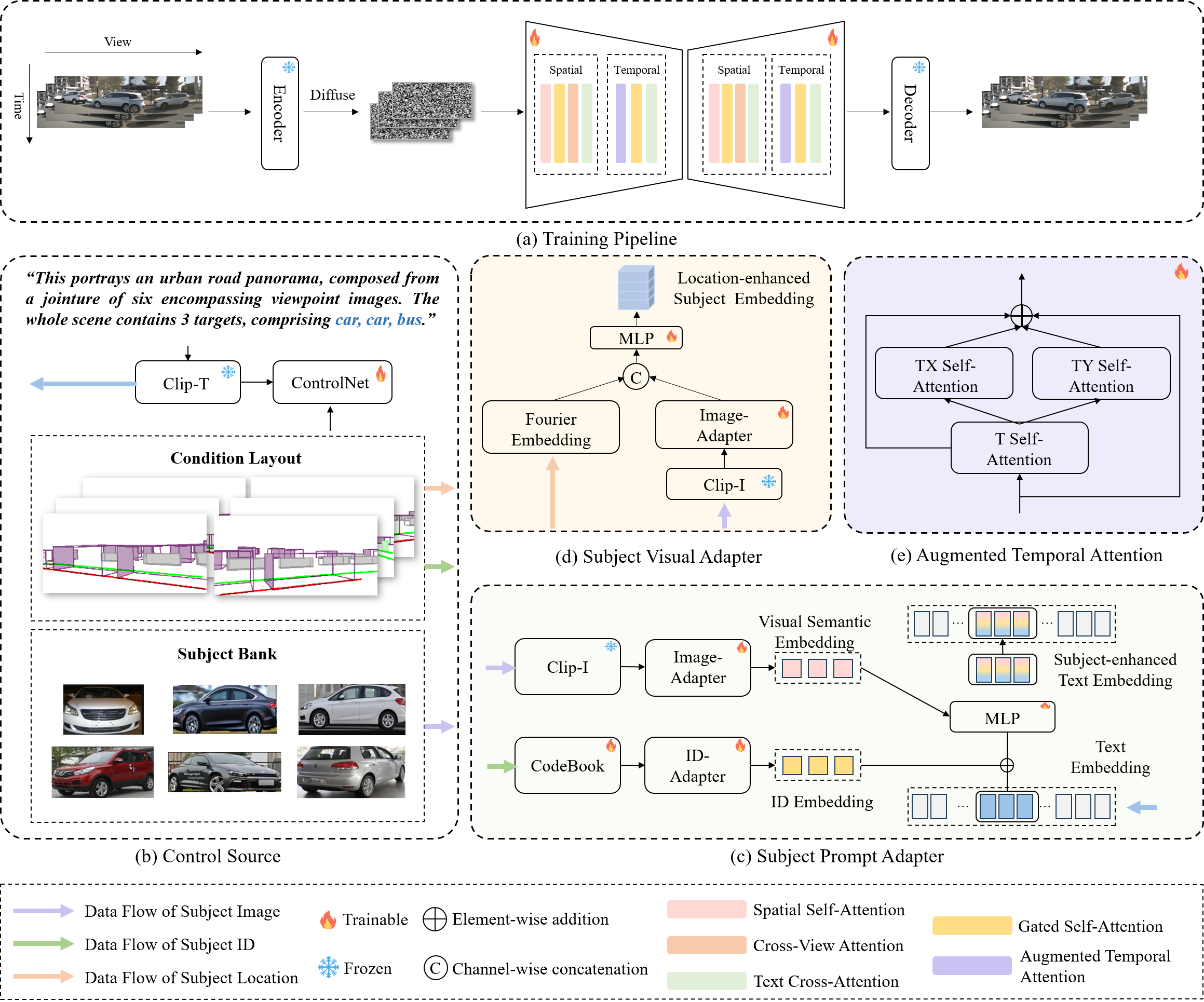
🔥 Stronger Generative Scalability for Autonomous Driving 🔥
|
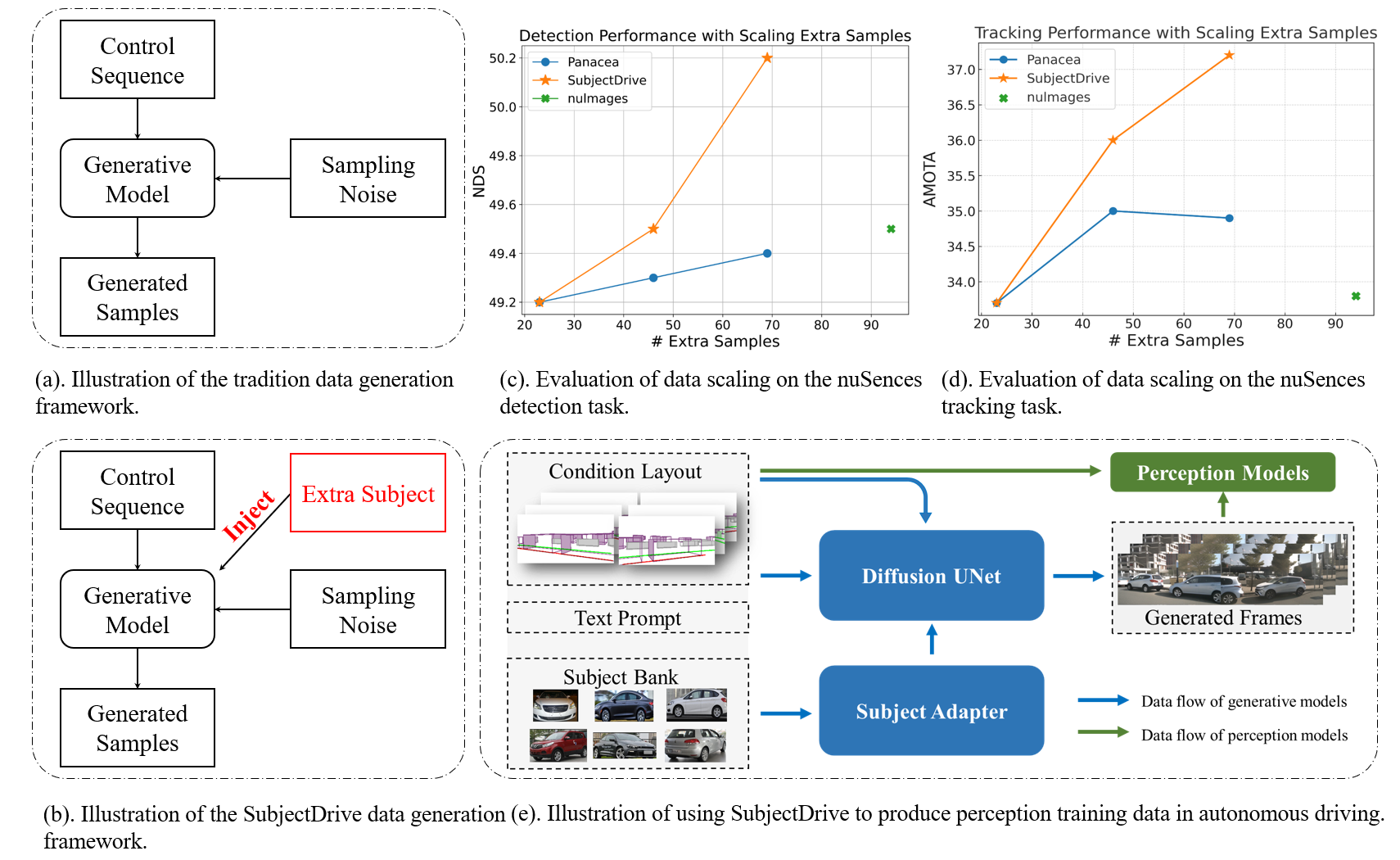
Overview of the proposed SubjectDrive framework and its effectiveness in enhancing BEV perception tasks. (a) Traditional data generation framework that uses the control sequence and sampling noise to generate synthetic data. (b) Compared with the traditional framework, our SubjectDrive introduces additional synthesis diversity by incorporating extra subject control. (c)-(d) Evaluation of detection and tracking performance with data scaling. (e) Illustration of using the SubjectDrive framework to produce perception training data in autonomous driving.